ECE 5760 | AV1 Decoding
Hardware “Accelerated” AV1 Decoding" using an FPGA
ECE 5760 - Hardware Acceleration via FPGA final project.
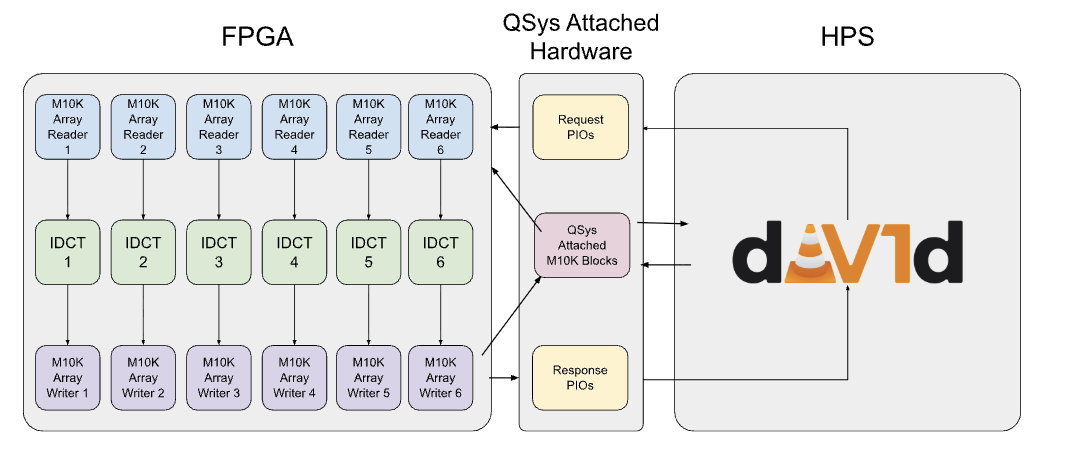
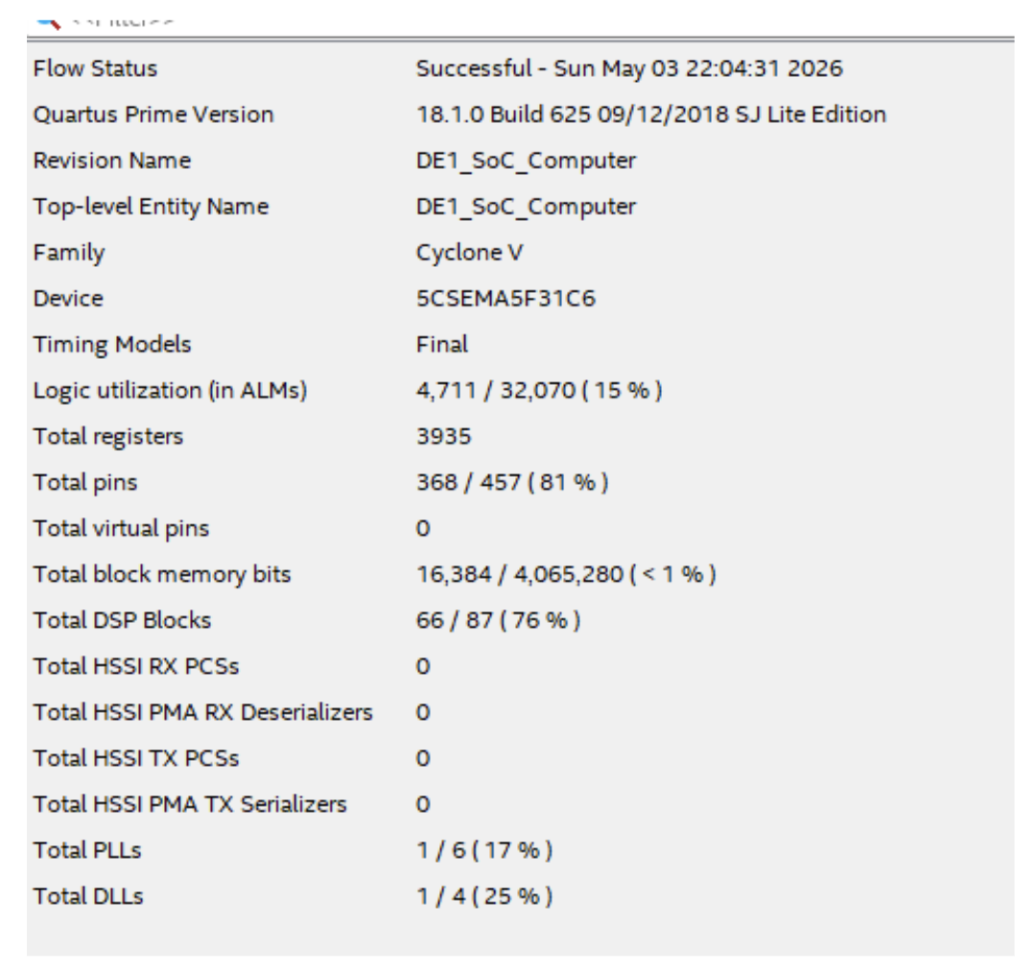
We integrated custom FPGA
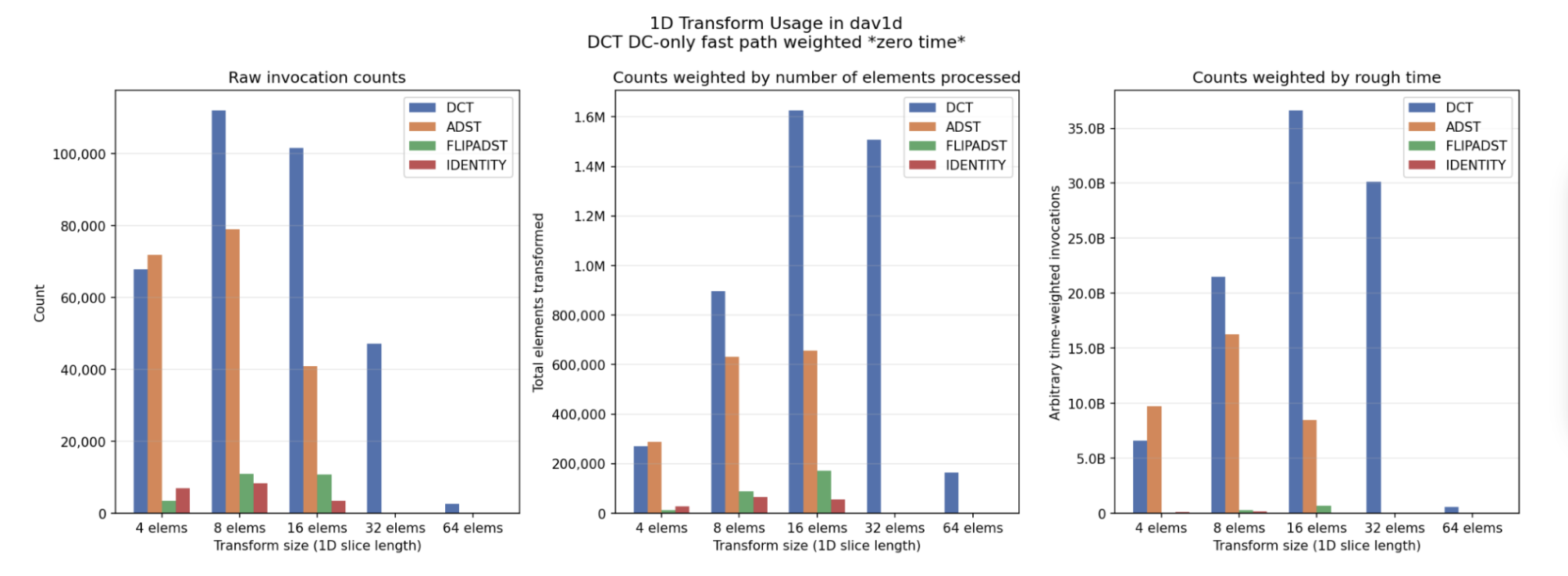
inverse discrete-cosine-transform (DCT) blocks with the open-source dav1d AV1 decoder running on the DE1-SoC HPS.
Note: We did not manage to achieve performance gains over dav1d's optimized C and ARM assembly paths, but the project was a useful learning experience.